在当今数据驱动的时代,高效处理实时信息流已成为企业技术架构的核心需求。作为分布式消息队列领域的标杆,Apache Kafka凭借其高吞吐、低延迟的特性,成为金融、电商、物联网等场景的首选工具。本文将从实际应用角度出发,为开发者和技术决策者提供一份详尽的Kafka获取与部署指南。
一、核心特性与行业地位
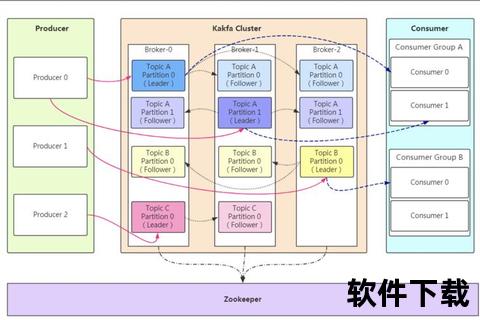
Kafka的架构设计完美平衡了性能与可靠性,其核心优势体现在三个方面:
1. 分布式高可用架构:通过分区(Partition)和副本机制(Replica)实现数据冗余,即使单节点故障也能保障服务连续性。
2. 万亿级消息处理能力:实测单集群每秒可处理数百万条消息,支持PB级数据存储。
3. 生态兼容性:与Spark、Flink等主流计算框架无缝集成,并通过Connect组件实现数据库同步。
在证券交易系统中,Kafka承载着每秒数十万笔订单的实时撮合;在智能物流领域,它支撑着千万级IoT设备的实时位置追踪。这些应用场景验证了其作为基础设施的稳定性。
二、精准获取安装资源
2.1 官方渠道下载
1. 访问Apache官网:进入[kafka./downloads],选择与JDK版本匹配的安装包(推荐3.7.0+版本)。
2. 校验文件完整性:通过SHA-512校验码验证下载包是否被篡改,避免供应链攻击。
3. 镜像加速:国内用户可使用清华镜像源缩短下载时间,替换URL中的`www.`为`mirrors.tuna..cn/apache`。
2.2 环境预检清单
三、全流程部署指南(以CentOS为例)
3.1 单机快速部署
bash
解压至指定目录
tar -xzf kafka_2.13-3.7.0.tgz -C /opt
修改基础配置
vim config/server.properties
broker.id=0
listeners=PLAINTEXT://:9092
log.dirs=/data/kafka-logs
启动服务
bin/zookeeper-server-start.sh config/zookeeper.properties &
bin/kafka-server-start.sh config/server.properties
3.2 集群进阶配置
1. 节点规划:至少3个broker组成集群,分区副本数建议设置为2(确保数据高可用)。
2. 动态扩展:通过`bin/kafka-reassign-partitions.sh`实现业务无感知扩容。
3. 性能调优:
四、安全防护体系
1. 传输层加密:
2. 权限管控:
3. 漏洞防御:
五、应用实践与生态建设
5.1 典型使用场景
5.2 可视化监控
六、社区演进与技术前瞻
根据2024年开发者调查报告,Kafka在流处理场景的采用率增长35%,未来重点方向包括:
1. 无服务化架构:与Kubernetes深度集成,实现弹性伸缩
2. AI增强运维:通过机器学习预测集群故障
3. 量子安全:研发抗量子计算加密算法
作为现代数据管道的核心枢纽,Kafka的部署质量直接影响着整个系统的稳定性。建议企业建立专职运维团队,定期参与[Apache官方培训],同时关注[Confluent]等商业发行版的安全增强功能。在数字化转型浪潮中,掌握Kafka的深度应用将成为技术团队的核心竞争力。